本站5月29日消息,今晚,DeepSeek官宣R1模型完成小版本升級,當前版本為DeepSeek-R1-0528。
據介紹,DeepSeek-R1-0528仍然使用2024年12月所發布的DeepSeek V3 Base模型作為基座,但在后訓練過程中投入了更多算力,顯著提升了模型的思維深度與推理能力。
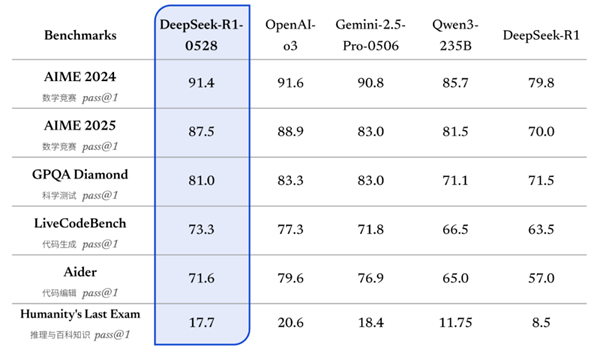
更新后的R1模型在數學、編程與通用邏輯等多個基準測評中取得了當前國內所有模型中首屈一指的優異成績,并且在整體表現上已接近其他國際頂尖模型,如o3與Gemini-2.5-Pro。
相較于舊版R1,新版模型在復雜推理任務中的表現有了顯著提升。
例如在AIME 2025測試中,新版模型準確率由舊版的70% 提升至87.5%,這一進步得益于模型在推理過程中的思維深度增強。
在AIME 2025測試集上,舊版模型平均每題使用12K tokens,而新版模型平均每題使用23K tokens,表明其在解題過程中進行了更為詳盡和深入的思考。
同時,DeepSeek蒸餾 DeepSeek-R1-0528的思維鏈后訓練Qwen3-8B Base,得到了DeepSeek-R1-0528-Qwen3-8B。
據了解,該8B模型在數學測試AIME 2024中僅次于DeepSeek-R1-0528,超越Qwen3-8B ( 10.0%),與Qwen3-235B相當。
DeepSeek相信,DeepSeek-R1-0528的思維鏈對于學術界推理模型的研究和工業界針對小模型的開發都將具有重要意義。
其他能力更新
幻覺改善:新版DeepSeek R1針對“幻覺”問題進行了優化。
與舊版相比,更新后的模型在改寫潤色、總結摘要、閱讀理解等場景中,幻覺率降低了45~50%左右,能夠有效地提供更為準確、可靠的結果。
創意寫作:在舊版R1的基礎上,更新后的R1模型針對議論文、小說、散文等文體進行了進一步優化,能夠輸出篇幅更長、結構內容更完整的長篇作品,同時呈現出更加貼近人類偏好的寫作風格。

鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



