好家伙,AI意外生成的內(nèi)核(kernel),性能比人類專家專門優(yōu)化過(guò)的還要好!
斯坦福最近披露了一組新發(fā)現(xiàn),結(jié)果真的太亮眼了。
由AI優(yōu)化的內(nèi)核,在常見深度學(xué)習(xí)操作上,翻倍超越原生PyTorch,性能至多可以提升近400%——
矩陣乘法(Matmul,F(xiàn)P32):性能達(dá)到PyTorch torch.matmul的101.3%。
二維卷積(Conv2D):性能達(dá)到 torch.nn.Conv2D的179.9%。
Softmax:性能達(dá)到 torch.softmax的111.8%。
層歸一化(LayerNorm):性能達(dá)到torch.nn.LayerNorm的484.4%。
Conv2D ReLU MaxPool組合操作:性能達(dá)到PyTorch參考實(shí)現(xiàn)的290.1%,以及torch.compile()參考實(shí)現(xiàn)的189.0%。
(在NVIDIA L40S GPU上進(jìn)行基準(zhǔn)測(cè)試,性能百分比定義為參考時(shí)間除以生成的kernel_size時(shí)間)

更驚人的是,這一切都是意外實(shí)現(xiàn)的。
研究團(tuán)隊(duì)本來(lái)的目標(biāo)是生成合成數(shù)據(jù)以訓(xùn)練內(nèi)核生成模型。
結(jié)果發(fā)現(xiàn),僅在測(cè)試階段生成的合成數(shù)據(jù)本身,竟然可以生成性能非常優(yōu)秀的內(nèi)核。
圍觀網(wǎng)友:沒(méi)想到AI也要取代內(nèi)核工程師了。
還有人發(fā)現(xiàn),除了性能大幅提升外,研究團(tuán)隊(duì)采用的方法也非常有趣:
他們沒(méi)有簡(jiǎn)單的在操作上逐步優(yōu)化(類似于爬坡算法),而是在每次迭代之間加入了一個(gè)語(yǔ)言推理的步驟,通過(guò)這種方式鼓勵(lì)搜索過(guò)程更加多樣化。
也就是說(shuō),他們是讓系統(tǒng)在每次改進(jìn)時(shí)通過(guò)類似“思考”的方式產(chǎn)生更多想法,從而找到更好的解決方案。

具體如何實(shí)現(xiàn),一起來(lái)看。
改代碼前先生成自然語(yǔ)言優(yōu)化思想
按照斯坦福團(tuán)隊(duì)博客的描述,這種內(nèi)核生成的思路非常簡(jiǎn)單——給定torch代碼,然后告訴都能寫編寫自定義內(nèi)核來(lái)替換torch算子。
這些內(nèi)核是用純CUDA-C編寫,無(wú)需使用CUTLASS和Triton等庫(kù)和DSL(Domain-Specific Language,領(lǐng)域?qū)S谜Z(yǔ)言)。
不同于傳統(tǒng)方法的是,模型并不是一上來(lái)就直接改代碼,而是先用自然語(yǔ)言生成優(yōu)化思想,然后再將這些思想轉(zhuǎn)化為新的代碼變體。
團(tuán)隊(duì)這樣做的理由是,“按順序修改”式的優(yōu)化思路缺乏多樣性,導(dǎo)致陷入局部極小值,重復(fù)訪問(wèn)同一類轉(zhuǎn)換或無(wú)休止地優(yōu)化沒(méi)有前景的軌跡。
為了進(jìn)一步增強(qiáng)思路多樣性,斯坦福團(tuán)隊(duì)還使用了多分支的探索模式。
具體來(lái)說(shuō),他們的方法并非每一步都只優(yōu)化一個(gè)候選方案,而是將每個(gè)想法分散開來(lái),使其衍生出多個(gè)實(shí)現(xiàn),并使用性能最高的內(nèi)核作為下一輪的種子。
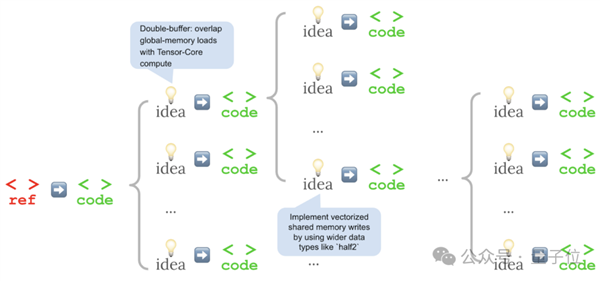
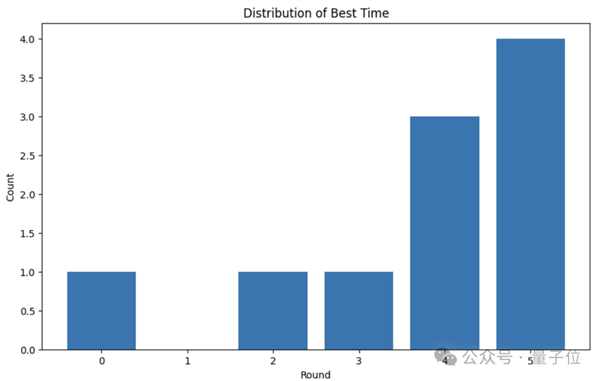
團(tuán)隊(duì)使用OpenAI o3和Gemini 2.5 Pro挑戰(zhàn)KernelBench 1級(jí)中的10個(gè)問(wèn)題,運(yùn)行多輪后,最佳內(nèi)核開始出現(xiàn)。
其中大多數(shù)最佳結(jié)果出現(xiàn)在后續(xù)輪次(總共5輪),并且主要是第4輪或第5輪。
KernelBench是斯坦福團(tuán)隊(duì)自己提出的一套AI生成內(nèi)核測(cè)試基準(zhǔn),基準(zhǔn)中的任務(wù)分為3個(gè)級(jí)別,其中1級(jí)是指單一原始操作(Single primitive operation),包括AI的基礎(chǔ)構(gòu)建塊(例如卷積、矩陣-向量與矩陣-矩陣乘法、損失函數(shù)、激活函數(shù)以及層歸一化)。
這一發(fā)現(xiàn)再加上之前DeepMind的AplhaEvolve,以及o3發(fā)現(xiàn)Linux的0day漏洞等一系列事件,讓網(wǎng)友們認(rèn)為Gemini 2.5Pro和o3的能力水平已經(jīng)達(dá)到了新的層級(jí)。
回到斯坦福的項(xiàng)目,在生成過(guò)程當(dāng)中,可以看到模型的生成思路開始顯現(xiàn)出與人類的經(jīng)驗(yàn)相似之處——
內(nèi)存訪問(wèn)優(yōu)化: 提高不同內(nèi)存層次結(jié)構(gòu)(全局內(nèi)存、共享內(nèi)存、寄存器)之間數(shù)據(jù)移動(dòng)的效率,并確保以最大化帶寬和最小化沖突的方式訪問(wèn)數(shù)據(jù);
異步操作和延遲隱藏: 通過(guò)將慢速操作(如全局內(nèi)存訪問(wèn))與計(jì)算或其他內(nèi)存?zhèn)鬏斨丿B,“隱藏”慢速操作的延遲;
數(shù)據(jù)類型和精度優(yōu)化: 盡可能使用低精度數(shù)據(jù)類型(如 FP16 或 BF16)以減少內(nèi)存帶寬要求、提高緩存效率;
計(jì)算和指令優(yōu)化:提高算術(shù)計(jì)算本身的效率,減少指令數(shù)量,或利用專門的硬件指令;
并行性和占用率增強(qiáng):最大化流多處理器(SM)上的活動(dòng)線程數(shù)量,以更好地隱藏延遲并提高整體吞吐量;
控制流和循環(huán)優(yōu)化:減少與循環(huán)、分支和索引計(jì)算相關(guān)的開銷。
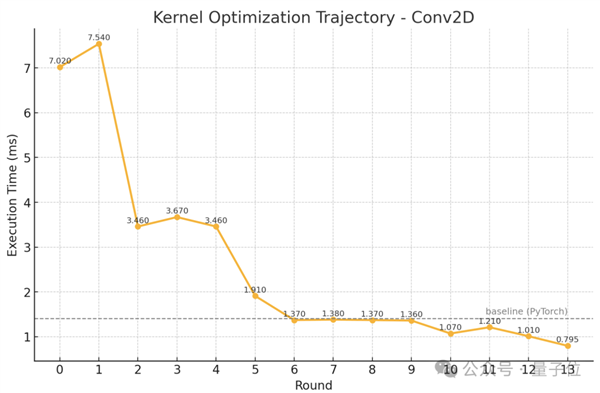
并且斯坦福團(tuán)隊(duì)還展示了一組具體的優(yōu)化軌跡,從中可以看出,并不是每一步優(yōu)化都一定能讓速度更快,但經(jīng)過(guò)多個(gè)步驟的組合,內(nèi)核的速度能夠得到大幅提升,并最終超越PyTorch。
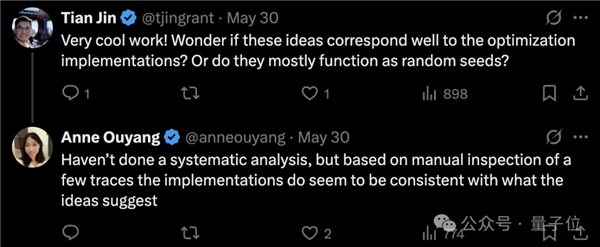
在具體實(shí)現(xiàn)上,有人詢問(wèn)AI生成CUDA內(nèi)核時(shí)的優(yōu)化建議,是否可以被轉(zhuǎn)化為對(duì)應(yīng)代碼實(shí)現(xiàn)、還是說(shuō)只是觸發(fā)了隨機(jī)探索?
作者回應(yīng)說(shuō),盡管還沒(méi)有進(jìn)行更嚴(yán)謹(jǐn)?shù)南到y(tǒng)驗(yàn)證,但是手動(dòng)檢查的案例中,生成的CUDA視線與提出的優(yōu)化建議是大致匹配的。
即AI并不是在完全隨機(jī)做優(yōu)化,而是確實(shí)在嘗試實(shí)現(xiàn)它自己提出的策略。
華人主創(chuàng)團(tuán)隊(duì)意外發(fā)現(xiàn)
這項(xiàng)研究共有三位作者:Anne Ouyang、Azalia Mirhoseini和Percy Liang。
Ouyang目前是斯坦福大學(xué)擴(kuò)展智能實(shí)驗(yàn)室的博士生,她本碩畢業(yè)于麻省理工,曾在英偉達(dá)cuDNN團(tuán)隊(duì)工作。

Percy Liang是斯坦福大學(xué)計(jì)算機(jī)科學(xué)副教授兼統(tǒng)計(jì)學(xué)助理教授,目前擔(dān)任斯坦福基礎(chǔ)模型研究中心主任。
曾和李飛飛一起發(fā)布、推進(jìn)了多項(xiàng)研究工作。

Azalia Mirhoseini是斯坦福大學(xué)計(jì)算機(jī)科學(xué)助理教授、斯坦福擴(kuò)展實(shí)驗(yàn)室創(chuàng)始人。她曾在DeepMind、Google Brain以及Anthropic工作過(guò)。
她此前參與的研究包括MoE、芯片設(shè)計(jì)算法AlphaChip等。

本次研究,本來(lái)是希望生成數(shù)據(jù)來(lái)訓(xùn)練內(nèi)核生成模型。
但是在過(guò)程中卻出現(xiàn)了意想不到的結(jié)果,僅在測(cè)試階段生成的合成數(shù)據(jù)本身,竟然可以生成性能非常優(yōu)秀的內(nèi)核。
因?yàn)檫@些內(nèi)核利用了此前被認(rèn)為很難實(shí)現(xiàn)的高級(jí)優(yōu)化和硬件特性,所以團(tuán)隊(duì)決定以博客形式分享此次成果。
不過(guò)具體是如何生成數(shù)據(jù)的,研究團(tuán)隊(duì)暫時(shí)不對(duì)外發(fā)布,只是提到了這種設(shè)計(jì)理念也很簡(jiǎn)單。
最關(guān)鍵的還是,它已經(jīng)展示出了巨大潛力。
此外,研究團(tuán)隊(duì)也認(rèn)為此次發(fā)現(xiàn)也與最近的一些趨勢(shì)相呼應(yīng)——大規(guī)模再訓(xùn)練已不是必需。
有時(shí),聰明的搜索和分支策略,可以解鎖科學(xué)創(chuàng)新并解決復(fù)雜問(wèn)題,通過(guò)verifier進(jìn)行廣泛搜索還能有更多收獲。
將強(qiáng)大推理能力與同時(shí)探索多個(gè)假設(shè)結(jié)合起來(lái),能帶來(lái)更好結(jié)果。就像AlphaEvolve、AlphaEvolution、 Gemini 2.5 Pro深度思考一樣。
最后,團(tuán)隊(duì)表示這項(xiàng)研究還有很多可優(yōu)化的空間。比如他們手頭上就還在優(yōu)化兩個(gè)維度:
FP16 Matmul:52% performance of torch.matmul
FP16 Flash Attention:9% performance of torch.nn.functional.scaled_dot_product_attention
與FP16或BF16相比,F(xiàn)P32在新推出硬件上的優(yōu)化程度通常比較低,這也是為何使用FP32內(nèi)核比PyTorch更容易實(shí)現(xiàn)性能提升。
他們表示,雖然現(xiàn)在還有不少限制,但是對(duì)于未來(lái)前景還是很樂(lè)觀的。
畢竟最開始,他們連能正常運(yùn)行的內(nèi)核都生成不了,但是通過(guò)不斷優(yōu)化搜索方法,已經(jīng)能讓flash attention的性能提升到了一個(gè)不錯(cuò)的水平。
值得一提的是,搜索使用的資源也很少,大概只用了300萬(wàn)token輸入和400萬(wàn)token輸出。
One More Thing
實(shí)際上,不只是一個(gè)團(tuán)隊(duì)在嘗試開發(fā)內(nèi)核大模型。
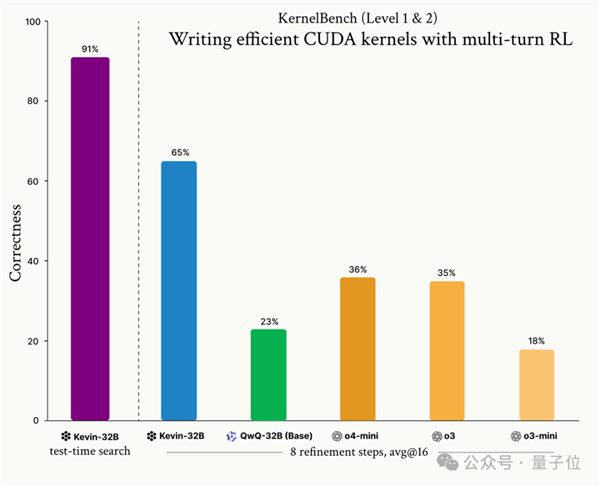
就在5月,開發(fā)了Devin的Cognition開源了首個(gè)通過(guò)強(qiáng)化學(xué)習(xí)即可編寫CUDA內(nèi)核的大模型Kevin-32B。
它基于QwQ-32B在KernelBench數(shù)據(jù)集上使用GRPO,實(shí)現(xiàn)了多輪強(qiáng)化學(xué)習(xí),性能優(yōu)于o3、o4-mini。
參考鏈接:
[1]https://crfm.stanford.edu/2025/05/28/fast-kernels.html
[2]https://x.com/anneouyang/status/1928124885567467768
[3]https://x.com/cognition_labs/status/1919835720493236295
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。



