北京時間6月6日,谷歌推出升級預覽版大模型Gemini 2.5 Pro(0605),并表示這會在幾周后成為正式的穩定版本,適用于企業級應用。
Gemini 2.5 Pro是谷歌旗艦模型系列,在前三個月公布了幾個預覽版,此前也一直在大模型競技場LMArena排名第一,這一次更新的版本各方面的分數都超過了此前的版本,繼續排在榜一。
不過,第一財經也詢問了一些開發者,他們認為,不能完全相信榜單,要看實際體驗和絕大多數開發者的選擇,此前Gemini的模型表現各有優劣,開發者評價兩極分化,目前剛出來大家或許要用一用才能有更客觀的評價。
根據谷歌官方博客,最新2.5 Pro 在多項AI性能基準測試中取得了更高的分數,在 LMArena上Elo分數(衡量模型相對技能水平的評分)提升了24分,目前以1470分的成績保持領先。
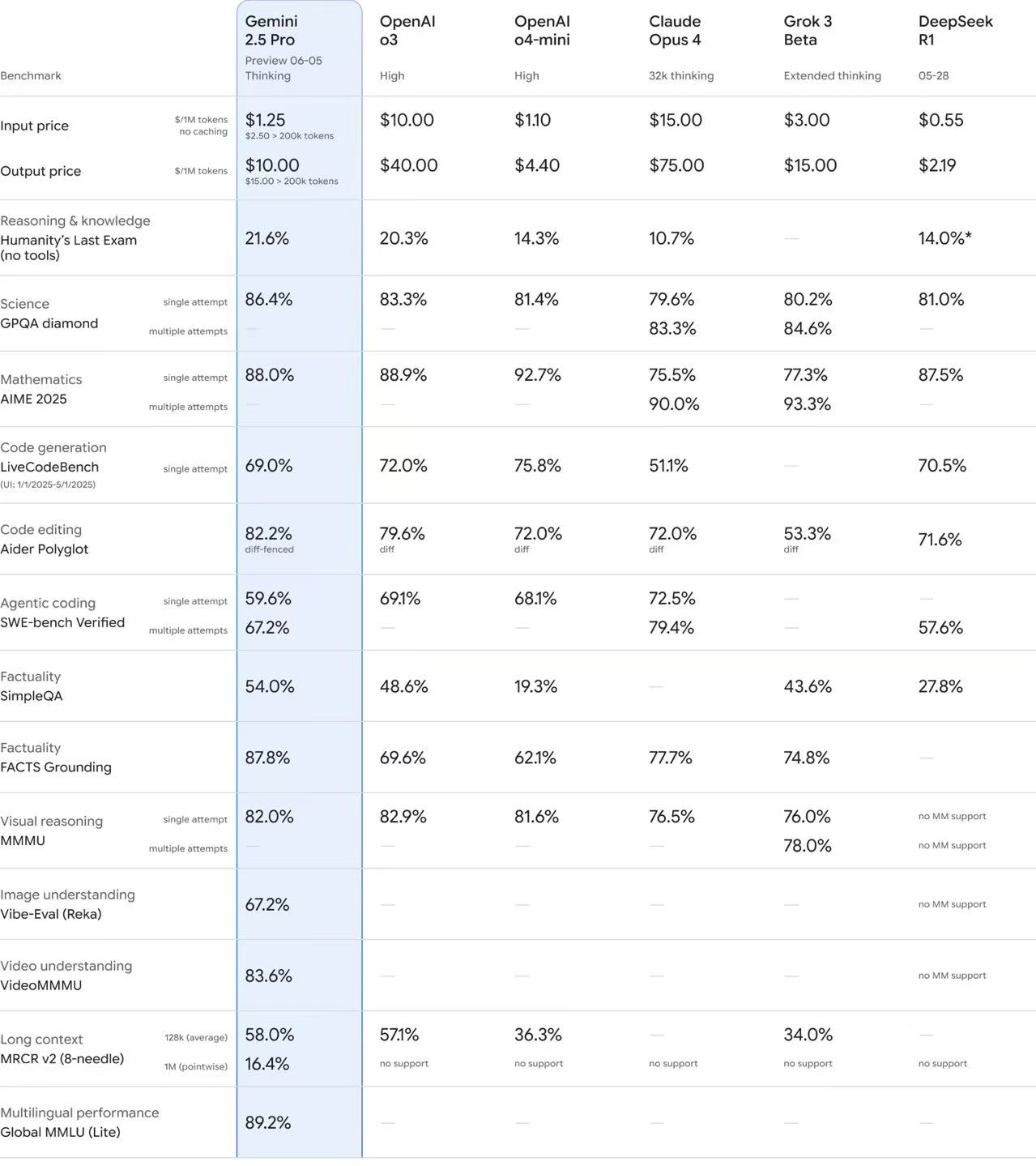
具體領域上,谷歌稱,最新模型在代碼方面繼續表現出色,在 Aider Polyglot 等高難度編程基準測試中保持領先。此外,它在 GPQA(研究生級別的問答測試)中的成績超過了OpenAI的o3、Claude 4以及DeepSeek-R1的最新版。在“人類的最后考試(HLE) ” 中成績達到21.6%,比OpenAI的o3多出 1.3個百分點。
在谷歌模型發布后,業界知名的測評方大模型競技場 (lmarena.ai)發布了一份新的榜單,顯示2.5 Pro新版在總分和所有子榜單位列第一,包括文本、視覺、數學、創意等。
不過,“高分低能”的產品此前也有過,不乏開發者對這個榜單存疑。例如,從編程體驗上來說,Anthropic的Claude系列模型是公認較為好用的基座模型,此次在榜單的成績并不突出。有海外網友表示,2.5 Pro新版的表現確實很好,但是不如Claude 4 Opus。
有行業人士認為,這一問題或許是榜單評測問題,只是讓AI完成基礎的任務,但對Agent的能力評測有限,但從實際應用過程中,Claude模型在Agent方面做了專門優化,可以在大規模、系統化、長時間的編程任務中表現出色,和行業拉開距離。而谷歌在Agent方向還沒怎么發力。
一位開發者用C 編程語言較多,他對記者表示,Claude比Gemini強太多,“任何Claude和o3無法解決的問題,Gemini從沒有一個能解決;但反之,Gemini 寫不對的,往往Claude能寫對。”
上述開發者認為,Gemini擅長的是長上下文和多模態,而Claude前端更優,目前看可能還是這一格局。
不過,另一位用Python和typescript編程語言的開發者體驗并不相同,最近一個月,他無論在工作場景還是Cursor場景都全面轉為了Gemini 2.5 pro,發現代碼寫得比Claude 3.7好,生成的網頁更漂亮,寫出來的文案也更好。
目前看起來,在不同的生產場景和個性化工作中,各個模型的體驗和口碑并不相同。
大模型競爭進入下半場,模型基礎能力差距逐漸縮小,模型之間的較量正在從單純的跑分轉向更復雜的維度,模型的真正價值,越來越取決于在特定場景下的表現能否贏得開發者的投票。
不過,除開能力,使用成本也是開發者較為看重的一個因素,目前來看,Gemini比OpenAI的 o3、Claude 4 Opus和Grok 3都要更有性價比,但仍然是國內DeepSeek的R1最便宜。
Gemini 2.5 pro的輸入價格1.25美元,輸出為10 美元/百萬Tokens。而o3在輸入和輸出價格方面則高至10美元和40美元每百萬Tokens ,Claude 4 Opus價格更高。針對此次更新,谷歌表示新模型引入了“思考預算”功能,能讓開發者更好地控制成本和延遲。
榜單分數是起點,真正的較量,在無數開發者和企業的工作和落地中展開。誰能更好地解決核心問題,誰就能贏得競爭的主動權。
幫企客致力于為您提供最新最全的財經資訊,想了解更多行業動態,歡迎關注本站。鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



